안녕하세요, 코린이의 코딩 학습기 채니 입니다.
개인 포스팅용으로 내용에 오류 및 잘못된 정보가 있을 수 있습니다.
컬렉션이란?
- 동일한 타입을 묶어 관리하는 자료 구조
컬렉션 프레임워크란?
- 리스트, 스택, 큐, 트리 등의 자료구조에 정렬, 탐색 등의 알고리즘을 구조화해 놓은 프레임워크
- 여러 개의 데이터 묶음 자료를 효과적으로 처리하기 위해 구조화된 클래스 또는 인터페이스의 모음
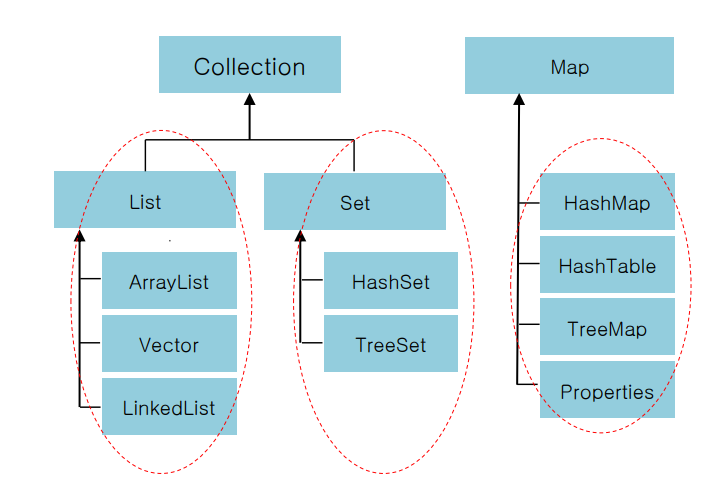
컬렉션의 특성에 따라 구분하면 크게 List<E>, Set<E>, Map<K, V>로 나뉩니다.
메모리의 입출력 특성에 따라 기존 컬렉션 기능을 확장/조합한 Stack<E>, Queue<E>도 있습니다.(사진에선 누락)
☞ Map<K, V> 컬렉션 인터페이스
- 사진 상에도 나와있듯이, Map<K, V> 컬렉션은 상속 구조상 List<E>, Set<E>와 분리 (별도 인터페이스 존재)
- Key(키)와 Value(값)의 한 쌍으로 데이터 저장
- 한 쌍의 데이터를 '엔트리'라고 하며, Map.Entry 타입으로 정의
- 데이터를 엔트리 단위로 입력 받음
- Key값으로 Value를 가져오므로 Key 값은 중복 불가, Value 값은 중복 가능
TreeMap<K, V>의 주요 메소드
| 구분 | 리턴 타입 | 메소드명 | 기능 |
| 데이터 추가 | V | put(K key, V value) | 입력매개변수의 (key, value)를 Map 객체에 추가 |
| void | putAll(Map<? extends K, ? extends V> | 입력매개변수의 Map 객체를 통째로 추가 | |
| 데이터 변경 | V | replace(K key, V value) | Key에 해당하는 값을 Value 값으로 변경(old 값 리턴) (단, 해당 Key가 없으면 null 리턴) |
| boolean | replace(K key, V oldValue, V newValue) | (key, oldValue)의 쌍을 갖는 엔트리에서 oldValue를 newValue로 변경 (단, 해당 엔트리가 없으면 null 리턴) |
|
| 데이터 정보 추출 |
V | get(Obejct key) | 매개변수의 Key 값에 해당하는 oldValue를 리턴 |
| boolean | containsKey(Object key) | 매개변수의 Key 값이 포함돼 있는 지 여부 | |
| boolean | containsValue(Object value) | 매개변수의 Value 값이 포함돼 있는지 여부 | |
| Set<K> | keySet() | Map 데이터들 중 Key들만 뽑아 Set 객체로 리턴 | |
| Set<Entry<K, V>> | entrySet() | Map의 각 엔트리들을 Set 객체로 담아 리턴 | |
| int | size() | Map에 포함된 엔트리의 개수 | |
| 데이터 삭제 | V | remove(Object key) | 입력매개변수의 Key를 갖는 엔트리 삭제 (단, 해당 Key가 없으면 아무런 동작을 하지 않음) |
| boolean | remove(Object key, Object value) | 입력매개변수의 (key, value)를 갖는 엔트리 삭제 (단, 해당 엔트리가 없으면 아무런 동작을 하지 않음) |
|
| void | clear() | Map 객체 내의 모든 데이터 삭제 | |
| 데이터 검색 |
K | firstKey() | Map 원소 중 가장 작은 Key 값 리턴 |
| Map.Entry<K, V> | firstEntry() | Map 원소 중 가장 작은 Key 값을 갖는 엔트리 리턴 | |
| K | lastKey() | Map 원소 중 가장 큰 Key 값 리턴 | |
| Map.Entry<K, V> | lastEntry() | Map 원소 중 가장 큰 Key 값은 갖는 엔트리 리턴 | |
| K | lowerKey(K key) | 매개변수로 입력된 Key 값보다 작은 Key 값 중 가장 큰 Key 값 리턴 | |
| Map.Entry<K, V> | lowerEntry(K key) | 매개변수로 입력된 Key 값보다 작은 Key 값 중 가장 큰 Key 값을 갖는 엔트리 리턴 | |
| K | higherKey(K key) | 매개변수로 입력된 Key 값보다 큰 Key 값 중 가장 작은 Key 값 리턴 | |
| Map.Entry<K, V> | higherEntry(K key) | 매개변수로 입력된 Key 값보다 큰 Key 값 중 가장 작은 Key 값을 갖는 엔트리 리턴 | |
| 데이터 추출 |
Map.Entry<K, V> | pollFirstEntry() | Map 원소 중 가장 작은 Key 값을 갖는 엔트리를 꺼내 리턴 |
| Map.Entry<K, V> | pollLastEntry() | Map 원소 중 가장 큰 Key 값을 갖는 엔트리를 꺼내 리턴 | |
| 데이터 부분 집합 생성 |
SortedMap<K, V> | headMap(K toKey) | toKey 미만의 Key 값을 갖는 모든 엔트리를 포함한 Map 객체 리턴(toKey 미포함) |
| NavigableMap<K, V> | headMap(K toKey, boolean inclusive) | toKey 미만/이하의 Key 값을 갖는 모든 엔트리를 포함한 Map 객체 리턴 (inclusive=true이면 toKey 포함, inclusive=false이면 toKey 미포함) |
|
| SortedMap<K, V> | tailMap(K fromKey) | fromKey 이상인 Key 값을 갖는 모든 엔트리를 포함한 map 객체 리턴 (fromKey 포함) |
|
| NavigableMap<K, V> | tailMap(K fromKey, boolean inclusive) | fromKey 초과/이상인 Key 값을 갖는 모든 엔트리를 포함한 Map 객체 리턴 (inclusive=true이면 fromKey 포함, inclusive=false이면 fromKey 미포함) |
|
| SortedMap<K, V> | subSet(K fromKey, K toKey) | fromKey 이상 toKey 미만의 Key 값을 갖는 모든 엔트리를 포함한 Map 객체 리턴 (fromKey 포함, toKey 미포함) |
|
| NavigableMap<K, V> | subSet(K fromKey, boolean frominclusive, K toKey, boolean toinclusive) | fromKey 초과/이상 toKey 미만/이하인 Key 값을 갖는 모든 엔트리를 포함한 map 객체 리턴 (frominclusive=true/false이면 fromKey 포함/미포함, toinclusive=true/false이면 toKey 포함/미포함) |
|
| 데이터 정렬 |
NavigableSet<K, V> | descendingKeySet() | Map에 포함된 모든 Key 값의 정렬을 반대로 변환한 Set 객체 리턴 |
| NavigableMap<K, V> | descendingMap() | Map에 포함된 모든 Key 값의 정렬을 반대로 변환한 Map 객체 리턴 |
☞ TreeMap<K, V>
- 데이터 입력 순서와 상관없이 데이터의 Key 값의 크기 순으로 저장
- SortedMap<K, V>와 NavigableMap<K, V> 인터페이스의 자식 클래스
- TreeMap<K, V> 생성자로 객체를 생성해도 Map<K, V> 타입으로 선언하면 정렬 및 검색 기능 사용 불가
TreeMap<K, V> 객체 생성
Map<제네릭 타입 지정, 제네릭 타입 지정> 참조변수 = new TreeMap<>(); //Map<K, V> 메소드만 사용 가능
TreeMap<제네릭 타입 지정, 제네릭 타입 지정> 참조변수 = new TreeMap<>();
Map<Integer, String> treeMap1 = new TreeMap<>(); //Map<K, V> 메소드만 사용 가능
TreeMap<Integer, String> treeMap2 = new TreeMap<>();
메소드 사용해보기
데이터 추가
for(int i = 20; i > 0; i-=2)
treeMap.put(i, i+"번째 데이터");
System.out.println(treeMap);
@콘솔출력값
{2=2번째 데이터, 4=4번째 데이터, 6=6번째 데이터 ... 18=18번째 데이터, 20=20번째 데이터}
데이터 검색
// firstKey() 가장 작은 Key 값 리턴
System.out.println(treeMap.firstKey());
// firstEntry() 가장 작은 Key 값을 가진 Entry 리턴
System.out.println(treeMap.firstEntry());
// lastKey() 가장 큰 Key 값 리턴
System.out.println(treeMap.lastKey());
// lastEntry() 가장 큰 Key 값을 가진 Entry 리턴
System.out.println(treeMap.lastEntry());
// lowerKey(K key) 매개변수의 key값 미만의 Key값 리턴
System.out.println(treeMap.lowerKey(11));
System.out.println(treeMap.lowerKey(10));
// higherKey(K key) 매개변수의 Key값 초과의 Key값 리턴
System.out.println(treeMap.higherKey(11));
System.out.println(treeMap.higherKey(10));
@콘솔출력값
10
8
12
12
데이터 꺼내기
// pollFirstEntry() 가장 첫번째 Entry를 꺼냄(삭제)
System.out.println(treeMap.pollFirstEntry()); //2=2번째 데이터
System.out.println(treeMap);
// pollLastEntry() 가장 마지막 Entry를 꺼냄(삭제)
System.out.println(treeMap.pollLastEntry()); //20=20번째 데이터
System.out.println(treeMap);
@콘솔출력값
2=2번째 데이터
{4=4번째 데이터, 6=6번째 데이터, ... 16=16번째 데이터, 18=18번째 데이터, 20=20번째 데이터}
20=20번째 데이터
{4=4번째 데이터, 6=6번째 데이터, ... 16=16번째 데이터, 18=18번째 데이터}
데이터 부분 집합 생성
// SortedMap<K, V> headMap(K toKey)
// toKey미만의 Key 값을 가진 엔트리를 포함한 Map리턴
SortedMap<Integer, String> sortedMap = treeMap.headMap(8);
System.out.println(sortedMap);
// NavigableMap<K, V> headMap(K toKey, boolean inclusive)
// toKey 미만/이하 Key 값을 가진 엔트리를 포함한 Map 리턴
NavigableMap<Integer, String> navigableMap = treeMap.headMap(8, true); //true = 이하, false = 미만
System.out.println(navigableMap);
@콘솔출력값
{4=4번째 데이터, 6=6번째 데이터}
{4=4번째 데이터, 6=6번째 데이터, 8=8번째 데이터}
// SortedMap<K, V> tailMap(K toKey)
// toKey 이상의 Key 값을 가진 엔트리를 포함한 Map 리턴
sortedMap = treeMap.tailMap(14);
System.out.println(sortedMap);
// NavigableMap<K, V> tailMap(K toKey, boolean inclusive)
// toKey 이상/초과의 Key 값을 가진 엔트리를 포함한 Map 리턴
navigableMap = treeMap.tailMap(14, false); //false = 초과, true = 이상
System.out.println(navigableMap);
@콘솔출력값
{14=14번째 데이터, 16=16번째 데이터, 18=18번째 데이터}
{16=16번째 데이터, 18=18번째 데이터}
// SortedMap<K, V> subMap(K fromKey, K toKey)
// fromKey 이상 ~ toKey 미만의 Key 값을 가진 Entry를 포함한 Map 리턴
sortedMap = treeMap.subMap(6, 10);
System.out.println(sortedMap);
// NavigableMap<K, V> subMap(K fromKey, boolean inclusive, K toKey, boolean inclusive)
// fromKey 이상/초과 ~ toKey 이하/미만의 Key 값을 가진 Entry를 포함한 Map 리턴
navigableMap = treeMap.subMap(6, false, 10, true);
System.out.println(navigableMap);
@콘솔출력값
{6=6번째 데이터, 8=8번째 데이터}
{8=8번째 데이터, 10=10번째 데이터}
데이터 정렬
// NavigableSet<K> descendingKeySet()
// Map에 포함된 모든 Key 값의 정렬을 반대로 변환한 Set리턴
NavigableSet<Integer> navigableSet = treeMap.descendingKeySet();
System.out.println(navigableSet);
System.out.println(navigableSet.descendingSet());
// NavigableMap<K, V> descendingMap()
// 모든 Key 값의 정렬을 반대로 변환한 Map 리턴
NavigableMap<Integer, String> navigableMap = treeMap.descendingMap();
System.out.println(navigableMap);
System.out.println(navigableMap.descendingMap());
@콘솔출력값
[18, 16, 14, 12, 10, 8, 6, 4]
[4, 6, 8, 10, 12, 14, 16, 18]
{18=18번째 데이터, 16=16번째 데이터, 14=14번째 데이터,... 6=6번째 데이터, 4=4번째 데이터}
{4=4번째 데이터, 6=6번째 데이터, 8=8번째 데이터, ... 16=16번째 데이터, 18=18번째 데이터}
크기 비교 메커니즘은 아래 포스팅을 참고!
https://chanychu.tistory.com/137?category=959041
컬렉션/Set<E>) TreeSet<E>, 주요 메소드, 크기 비교
안녕하세요, 코린이의 코딩 학습기 채니 입니다. 개인 포스팅용으로 내용에 오류 및 잘못된 정보가 있을 수 있습니다. 컬렉션이란? - 동일한 타입을 묶어 관리하는 자료 구조 컬렉션 프레임워크
chanychu.tistory.com
※ Do it! 자바 완전 정복을 참고하여 포스팅하였습니다.
'Java > Java' 카테고리의 다른 글
| 쓰레드) 쓰레드란?, 멀티쓰레드, 장단점, 쓰레드 우선 순위 (0) | 2022.04.03 |
|---|---|
| 컬렉션/Map<K, V>) Properties, 설정 파일 쓰고 읽어오기 (0) | 2022.04.02 |
| 컬렉션/Map<K, V>) LinkedHashMap<K, V>, 주요 메소드 (0) | 2022.04.02 |
| 컬렉션/Map<K, V>) HashMap<K, V>, 주요 메소드 (0) | 2022.04.02 |
| 컬렉션/Set<E>) TreeSet<E>, 주요 메소드, 크기 비교 (0) | 2022.04.01 |



