SMALL
안녕하세요, 코린이의 코딩 학습기 채니 입니다.
개인 포스팅용으로 내용에 오류 및 잘못된 정보가 있을 수 있습니다.
GROUP BY
- 테이블 전체 행을 특정 컬럼이 동일한 행끼리 그룹핑 처리
- group by절이 없다면, 테이블 모든 행이 하나의 그룹으로 처리
- group by에 명시한 컬럼만이 select절에 사용될 수 있음
부서 별로 급여 합계/평균
select
dept_code,
sum(salary) sum_sal,
trunc(avg(salary)) avg_sal
from
employee
group by
dept_code
order by
sum_sal desc;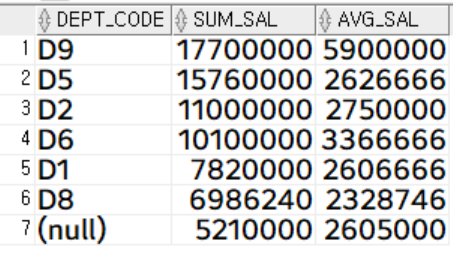
부서 별로 인원 수 조회 (인원 수 내림차순)
select
dept_code,
count(*) 인원수
from
employee
group by
dept_code
order by
인원수 desc;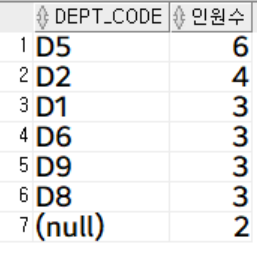
사원 테이블에서 J1 직급을 제외하고, 직급 별 사원 수, 평균 급여 조회 (직급별 오름차순 정렬)
select
job_code 직급,
count(*) || '명' 사원수,
trunc(avg(salary)) 평균급여
from
employee
where
job_code != 'J1'
group by
job_code
order by
직급;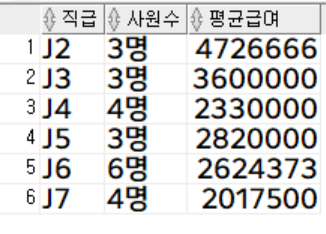
입사년도 별 사원 수 조회
※ 테이블 별칭에는 as, "" 불가
select
extract(year from hire_date) 입사년도,
count(*) || '명' 사원수
from
employee e -- 테이블 별칭에는 as, "" 불가
group by
extract(year from hire_date)
order by
입사년도;
성별 인원 수
select
decode(substr(emp_no, 8, 1), 1, '남', 3, '남', '여') 성별,
count(*) || '명' 인원수
from
employee
group by
decode(substr(emp_no, 8, 1), 1, '남', 3, '남', '여');
부서 별, 직급 별 인원 수를 조회
※ 실제로는 distinct 처리와 같이 두 컬럼의 값이 동일한 행을 그룹핑 (group by 컬럼 순서는 중요 X)
select
dept_code 부서,
job_code 직급,
count(*) 인원수
from
employee
group by
dept_code, job_code
order by
1, 2;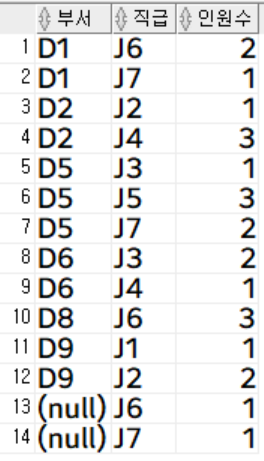
group by절의 컬럼이 두 개 이상인 경우에는, 해당 컬럼들의 값이 동일한 행들을 그룹핑하게 됩니다.
예를 들어서, 부서코드가 'D1'이면서 직급코드가 'J6'인 인원 수를 카운트 / 부서코드가 'D1'이면서 직급코드가 'J7'인 인원 수 카운트 .... 와 같이 두 컬럼을 묶어서 그룹처리하게 되는 것입니다.
LIST



