안녕하세요, 코린이의 코딩 학습기 채니 입니다.
개인 포스팅용으로 내용에 오류 및 잘못된 정보가 있을 수 있습니다.
SET OPERATOR
- 집합 연산자
- 두 개 이상의 결과 집합을 세로로 연결해서 하나의 가상 테이블 (relation) 생성
SET OPERATOR 조건
① select절의 컬럼 수가 동일해야함
② select절의 상응하는 컬럼의 자료형이 상호호환 (char/varchar2 연결 가능)
③ order by절은 마지막 결과 집합에서 단 한 번만 사용 가능
④ 컬럼명이 다른 경우, 첫 번째 결과 집합의 컬럼명 사용
집합 연산자 종류
① union
- 두 결과 집합을 연결하되, 중복 제거 / 첫 번째 컬럼 기준 오름차순 정렬 기능 지원
② union all
- 두 결과 집합을 그대로 연결
③ intersect
- 교집합
④ minus
- 차집합
부서코드가 'D5'인 사원 조회 (사번, 사원명, 부서코드, 급여)
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5';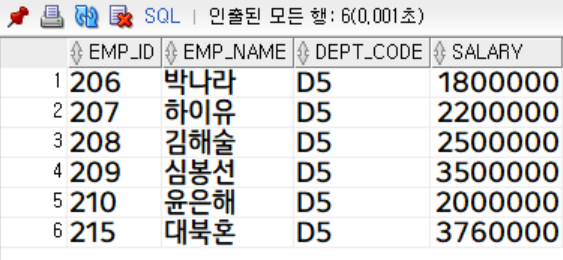
급여가 300만원 이상인 사원 조회 (사번, 사원명, 부서코드, 급여)
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;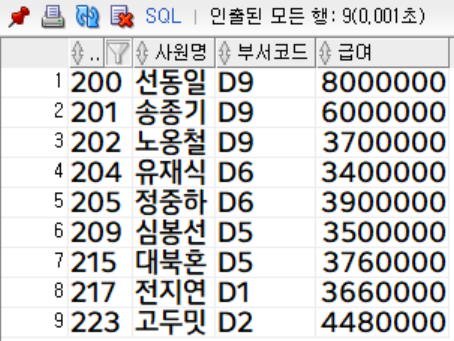
☞ union
- 중복 제거, 첫 번째 컬럼 기준 오름차순 지원
- 컬럼 수 불일치 시 (ORA-01789: query block has incorrect number of result columns 오류 발생)
- 컬럼 순서 불일치 시 (ORA-01790: expression must have same datatype as corresponding expression 오류 발생)
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5'
union
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000
order by
salary desc;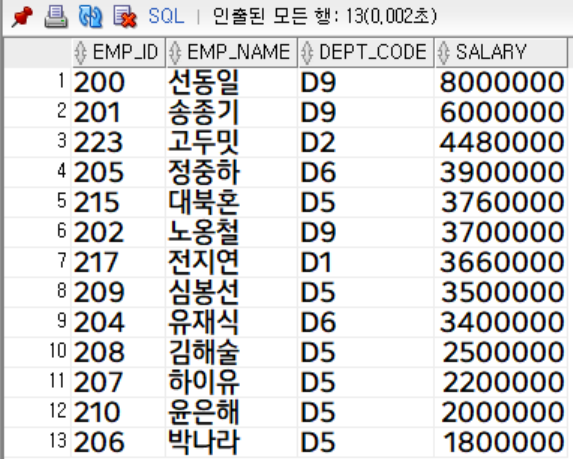
부서코드가 'D5'인 사원은 총 6명, 급여가 300만원 이상인 사원은 총 9명이였지만 union의 결과는 13행입니다.
그 이유는 '대북혼'과 '심봉선'이 중복 되므로 제거가 되었기 때문이죠.
또한 두 entity의 컬럼명이 상이한데, 첫 번째 결과 집합의 컬럼명으로 추출된 것을 확인할 수 있습니다.
이번엔 order by를 생략해보도록 하겠습니다.
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5'
union
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;
--order by
-- salary desc;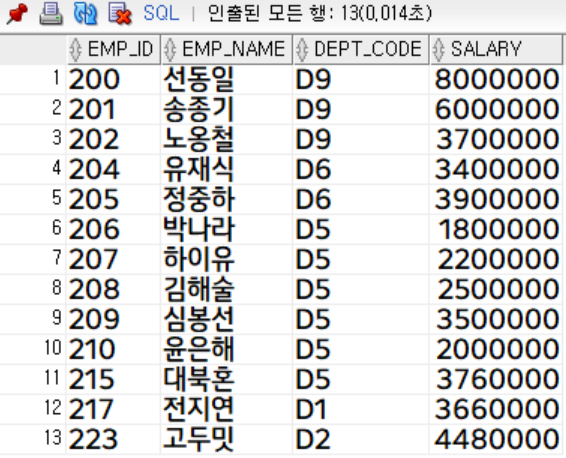
첫 번째 컬럼 (emp_id)가 오름차순으로 정렬되어 산출 된 것을 확인할 수 있습니다.
이렇듯 union은 자동으로 중복 제거 및 첫 번째 컬럼 오름차순 정렬을 지원해줍니다.
만일 컬럼 수가 일치하지 않는다면 어떻게 될까요?
select
emp_id,
emp_name,
dept_code
-- salary -- 컬럼 수 불일치(ORA-01789: query block has incorrect number of result columns 오류발생)
from
employee
where
dept_code = 'D5'
union
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;"ORA-01789: query block has incorrect number of result columns" 오류가 발생하게 됩니다.
만일 컬럼의 자료형이 호환되지 않는다면 어떻게 될까요?
select
emp_id,
emp_name,
salary, -- 자료형 불일치
dept_code -- 자료형 불일치 (ORA-01790: expression must have same datatype as corresponding expression)
from
employee
where
dept_code = 'D5'
union
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;"ORA-01790: expression must have same datatype as corresponding expression" 오류가 발생하게 됩니다.
만일 정렬을 두 번 이상 사용하게 된다면 어떻게 될까요?
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5'
order by
salary desc -- 오류 발생 (ORA-00933: SQL command not properly ended)
union
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
salary >= 3000000
order by
salary desc;"ORA-00933: SQL command not properly ended" 오류가 발생하게 됩니다.
이렇듯 반드시 컬럼 수와 자료형이 동일해야 하며, 정렬은 마지막에 단 한 번만 사용 가능합니다.
☞ union all
- 속도/성능이 union 대비 좋음
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5'
union all
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;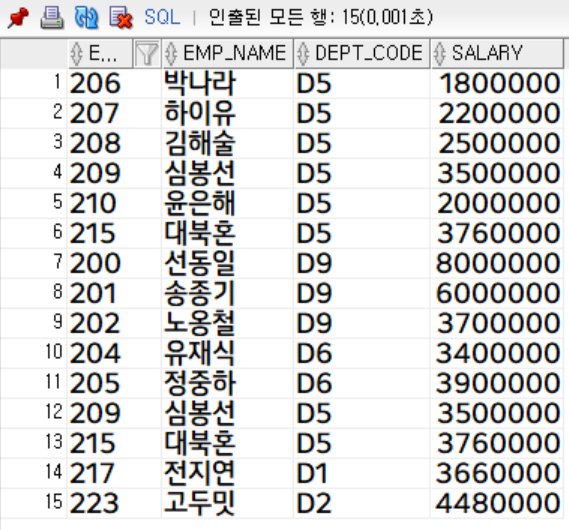
union과 다르게 15행이 추출된 것을 확인할 수 있으며, '대북혼', '심봉선'의 결과 값이 중복 되어 나온 것을 확인할 수 있습니다.
또한 첫번째 컬럼 emp_id 또한 정렬되지 않은 채로 추출 된 것을 확인할 수 있습니다.
이처럼 union all은 어떠한 조건/기능 지원 없이 테이블을 붙이는 것이기 때문에 속도/성능 면에서 union보다 우수합니다.
☞ intersect
- 중복된 행(모든 컬럼 값이 일치하는 경우)만 출력
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5'
intersect
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;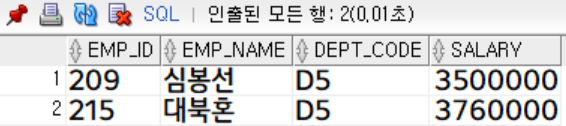
중복된 행 (심봉선, 대북혼)만 출력 되는 것을 확인할 수 있습니다.
☞ minus
- 위 결과 집합에서 아래 결과 집합과의 중복된 행을 제거하고 조회
select
emp_id,
emp_name,
dept_code,
salary
from
employee
where
dept_code = 'D5'
minus
select
emp_id 사번,
emp_name 사원명,
dept_code 부서코드,
salary 급여
from
employee
where
salary >= 3000000;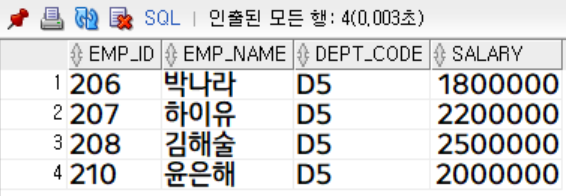
첫번째 결과 집합에서 두 번째 결과 집합과의 중복된 행을 제거 (심봉선, 대북혼)한 행들만 조회된 것을 확인할 수 있습니다.
@실습문제
-- @실습문제 : 두 달 전 판매데이터만 조회
-- 현재 조회 시 2022-02 데이터 출력
-- 2022-02에서 두 달 전 조회 시 2021-12 데이터 조회
select
*
from
tb_sales_2
where
to_char(sale_date, 'yyyy-mm') = to_char(add_months(sysdate, -2), 'yyyy-mm');
-- 판매 데이터 관리
-- 현재 월 데이터만 관리하다 다음 달이 되면 지난 달 판매데이터 테이블 생성 후 데이터를 분리해서 관리
-- 테이블 쪼개기
-- 2022-03
create table tb_sales_2_2022_03
as
select
*
from
tb_sales_2
where
to_char(sale_date, 'yyyy-mm') = to_char(add_months(sysdate, -1), 'yyyy-mm');
-- 2022-02
create table tb_sales_2_2022_02
as
select
*
from
tb_sales_2
where
to_char(sale_date, 'yyyy-mm') = to_char(add_months(sysdate, -2), 'yyyy-mm');
-- 현재 테이블에서 지난 2,3월 데이터 삭제
delete from
tb_sales_2
where
to_char(sale_date, 'yyyy-mm') in (to_char(add_months(sysdate, -2), 'yyyy-mm'), to_char(add_months(sysdate, -1), 'yyyy-mm'));
-- 데이터 마이그레이션(migration) 작업 후
select * from tb_sales_2;
select * from tb_sales_2_2022_03;
select * from tb_sales_2_2022_02;
commit;
-- 지난 3개월 데이터 조회
select * from tb_sales_2
union all
select * from tb_sales_2_2022_03
union all
select * from tb_sales_2_2022_02;
-- 지난 3개월 제품 별 총 판매량 조회
select
pname 제품명,
sum(pcount) 판매량
from
(
select * from tb_sales_2
union all
select * from tb_sales_2_2022_03
union all
select * from tb_sales_2_2022_02
)
group by
pname
order by
판매량 desc;
'DataBase > Oracle' 카테고리의 다른 글
| SUB-QUERY) 단일행 단일컬럼 서브쿼리 (0) | 2022.04.21 |
|---|---|
| SUB-QUERY) 서브쿼리란?, 서브쿼리의 조건 (0) | 2022.04.21 |
| JOIN/NON-EQUI-JOIN) NON-EQUI-JOIN (0) | 2022.04.19 |
| JOIN/EQUI-JOIN) MULTIPLE JOIN (0) | 2022.04.19 |
| JOIN/EQUI-JOIN) SELF JOIN (0) | 2022.04.19 |



