안녕하세요, 코린이의 코딩 학습기 채니 입니다.
개인 포스팅용으로 내용에 오류 및 잘못된 정보가 있을 수 있습니다.
WINDOW FUNCTION
- 행과 행 간의 관계를 쉽게 정의하기 위한 함수
- select절에서만 사용 가능

window_function(args) over ([partition by절] [order by절][windowing절])
- args : 윈도우 함수에 전달하는 인자 (0 ~ n)
- over절 : 행 그룹 지정, 그룹 당 결과 출력
- partition by : 윈도우 함수의 group by
- order by : 행 순서 지정
- windowing : 대상 행 지정
순위관련처리
☞ rank, dense_rank, row_number
- rank → order by 중복된 값이 있다면, 그 다음 순위는 중복된 만큼 건너뜀
- dense_rank → order by 중복된 값이 있어도 건너뛰지 않고, 순위 부여
- row_number → 중복 값 없이 순위 부여
select
emp_name,
salary,
rank() over (order by salary desc) as rank,
dense_rank() over (order by salary desc) as dense_rank,
row_number() over (order by salary desc) as row_number
from
employee;
salary의 값이 같은 '전형돈' '윤은해'를 비교해보면 차이를 확실히 알 수 있습니다.
중복된 값이 있으면 다음 순위를 건너뛰는 rank의 경우, 박나라가 21위가 아닌 건너뛴 22위인 것을 알 수 있고,
중복된 값이 있어도 건너뛰지 않고 순위를 부여하는 dense_rank의 경우, 박나라가 그대로 21위입니다.
반면에 중복 값 없이 순위 부여를 하는 row_number는 20, 21, 22위로 출력된 것을 확인할 수 있습니다.
select
*
from (
select
row_number() over (order by salary desc) as rank,
emp_name, salary
from
employee
)
where
rank between 1 and 10;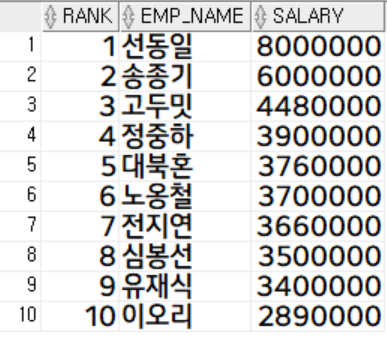
rank를 통해 탑 10을 추려낼 때도 역시 inline-view를 사용해줍니다.
where절에서 추려내는데 처리 순서가 from - where - select 순이므로 where절에서 'rank'를 찾을 수가 없기 때문이죠.
따라서 inline-view를 통해 처리해줘야 합니다.
부서별 급여 순위
select
emp_name,
dept_code,
salary,
dense_rank() over (partition by dept_code order by salary desc) rank_by_dept,
dense_rank() over (order by salary desc) rank
from
employee
order by
dept_code, rank_by_dept;
사원 테이블에서 입사일 순으로 top5 조회 (사번, 사원명, 부서명, 직급명, 입사일)
select
*
from (
select
row_number() over (order by hire_date) rank,
emp_id, emp_name,
(select dept_title from department where dept_id = e.dept_code) dept_title,
(select job_name from job where job_code = e.job_code) job_name,
hire_date
from
employee e
) e
where
rank < 6;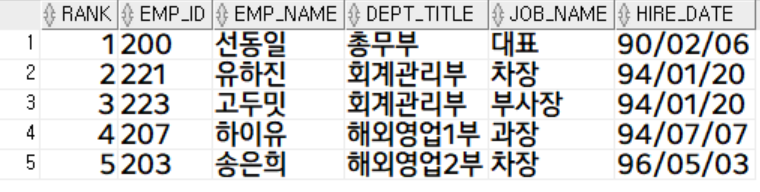
부서별 입사 순서 조회 (사원명, 부서명, 입사일, 입사순서)
select
emp_name,
(select dept_title from department where dept_id = e.dept_code) dept_title,
hire_date,
dense_rank() over (partition by dept_code order by hire_date) rank
from
employee e;
집계관련처리
☞ sum() over()
사원명, 급여, 전 사원의 급여 합계
select
emp_name,
salary,
sum(salary) over() as salary_sum
from
employee;
그룹함수의 sum()과는 확실히 다른 것을 알 수 있습니다.
그룹합수의 sum()은 일반 컬럼과 사용할 수 없었지만 sum() over()는 일반 컬럼과 함께 사용할 수 있습니다.
select
emp_name,
dept_code,
salary,
-- sum(salary) over() as salary_sum
sum(salary) over(partition by dept_code) as salary_sum_dept
from
employee;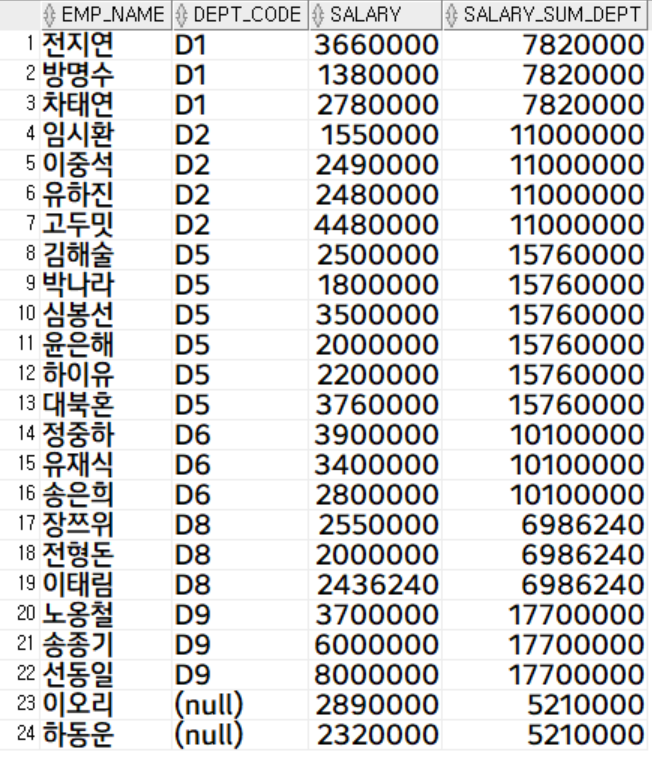
partition by를 이용해서 그룹핑하여 salary의 합을 구할 수도 있습니다.
select
emp_name,
dept_code,
salary,
-- sum(salary) over() as salary_sum
-- sum(salary) over(partition by dept_code) as salary_sum_dept
sum(salary) over(order by salary) as salary_sum_order
from
employee;

order by를 통해서도 정렬 순에 따라 급여를 합쳐 누계를 볼 수도 있습니다.
여기서 '전형돈'과 '윤은해'는 salary가 동일하기 때문에 두 salary 급액이 합쳐져서 더해진 것을 확인할 수 있는데,
이는 order by salary, emp_name 으로 세부 정렬을 통해 아래와 같이 해결할 수 있습니다.

select
emp_name,
dept_code,
salary,
-- sum(salary) over() as salary_sum
-- sum(salary) over(partition by dept_code) as salary_sum_dept
-- sum(salary) over(order by salary, emp_name) as salary_sum_order
sum(salary) over(partition by dept_code order by salary) as salary_sum --급여 순에 따른 누계
from
employee;
partition by와 order by를 이용하여 부서 별 급여 순에 따른 누계를 나타낼 수도 있습니다.
판매 데이터 누계
select
pname,
pcount,
sale_date,
sum(pcount) over(partition by pname order by sale_date) agg_sum
from (
select * from tb_sales_2_2022_02
union all
select * from tb_sales_2_2022_03
union all
select * from tb_sales_2
);
☞ avg() over()
select
emp_name,
dept_code,
salary,
trunc(avg(salary) over()) avg_sal,
trunc(avg(salary) over(partition by dept_code)) avg_sal_dept
from
employee;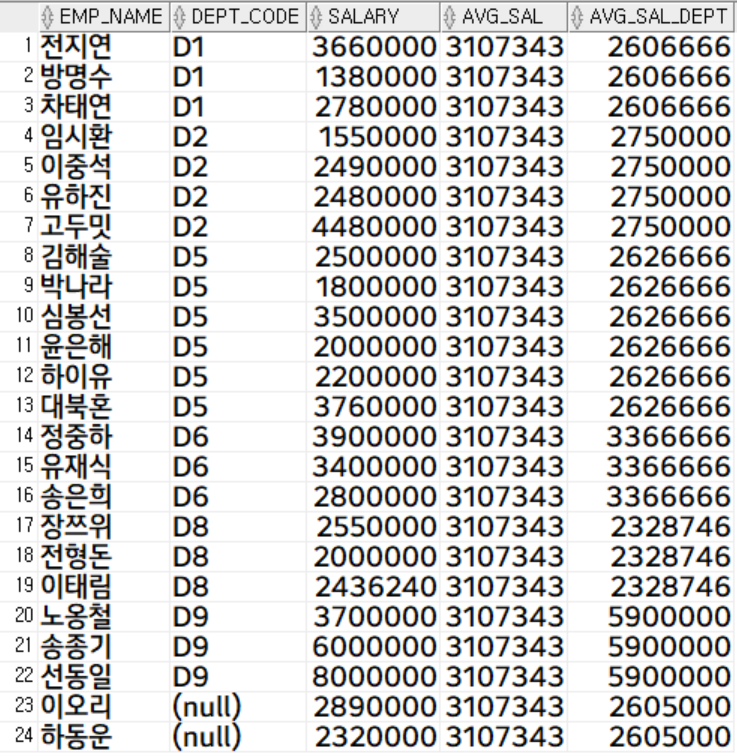
☞ listagg
- wm_concat(10g ~ 11g) 함수의 새로운 버전
- 조회된 결과를 하나의 컬럼으로 합쳐서 출력
select
listagg(emp_name, ', ') as 전체사원명
from
employee;
조회 결과를 하나의 컬럼으로 합쳐서 출력된 것을 확인할 수 있습니다.
이름 순으로 정렬하고 싶다면 over()절이 아닌 within group() 절을 통해서 order by할 수 있습니다.
select
-- listagg(emp_name, ', ') as 전체사원명,
listagg(emp_name, ', ') within group (order by emp_name)
from
employee;
이름 순으로 잘 정렬된 것을 확인할 수 있습니다!
grouping 처리
select
dept_code,
listagg(emp_name, ', ') within group (order by emp_id) over(partition by dept_code) list
from
employee;
over의 partition by를 이용해서 dept_code 별로 그룹핑하여 부서 list를 추출하였습니다.
중복 되는 값을 없애고 싶다면, distinct를 사용하거나 아예 group by 절을 사용할 수 있겠죠?
-- distinct 이용
select distinct
dept_code,
listagg(emp_name, ', ') within group (order by emp_id) over(partition by dept_code) list
from
employee
order by
1;
-- group by 이용
select
dept_code,
listagg(emp_name, ', ') within group(order by emp_id) list
from
employee
group by
dept_code;
'DataBase > Oracle' 카테고리의 다른 글
| DML) UPDATE 구문 (0) | 2022.04.26 |
|---|---|
| DML) INSERT 구문 (subquery 이용, insert all 이용) (0) | 2022.04.25 |
| 고급쿼리) TOP-N 분석 (rownum) (0) | 2022.04.22 |
| SUB-QUERY) 스칼라 서브쿼리, inline-view (0) | 2022.04.22 |
| SUB-QUERY) 상호연관 서브쿼리 (exists, not exists) (0) | 2022.04.21 |



